HDFS 读写过程分析
HDFS 是一个分布式文件系统,它和现有的分布式文件系统有很多共同点。但同时,它和其他的分布式文件系统的区别也是很明显的。HDFS是一个高度容错性的系统,适合部署在廉价的机器上。HDFS能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。HDFS 上读写文件的过程与我们平时使用的单机文件系统非常不同,本文就介绍 HDFS 上读写文件过程。
一、写文件过程
在 HDFS 文件系统上创建并写一个文件,流程如下图所示:
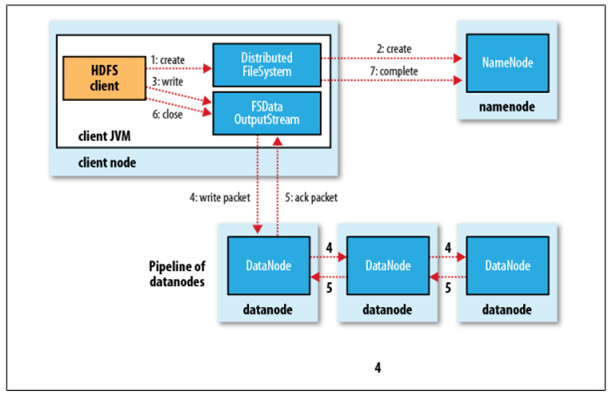
具体过程描述如下:
- Client 调用 DistributedFileSystem 对象的 create 方法,创建一个文件输出流(FSDataOutputStream)对象
- 通过 DistributedFileSystem 对象与 Hadoop 集群的 NameNode 进行一次RPC远程调用,在HDFS的 Namespace 中创建一个文件条目(Entry),该条目没有任何的 Block
- 通过 FSDataOutputStream 对象,向 DataNode 写入数据,数据首先被写入 FSDataOutputStream 对象内部的 Buffer 中,然后数据被分割成一个个 Packet 数据包
- 以Packet最小单位,基于 Socket 连接发送到按特定算法选择的 HDFS 集群中一组 DataNode(正常是3个,可能大于等于1)中的一个节点上,在这组 DataNode 组成的 Pipeline 上依次传输 Packet
- 这组 DataNode 组成的 Pipeline 反方向上,发送 ack ,最终由 Pipeline 中第一个 DataNode 节点将 Pipeline ack 发送给 Client
- 完成向文件写入数据,Client 在文件输出流(FSDataOutputStream)对象上调用 close 方法,关闭流
- 调用 DistributedFileSystem 对象的 complete 方法,通知 NameNode 文件写入成功
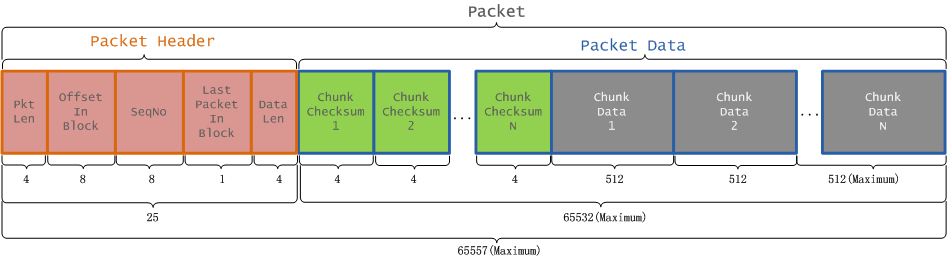
Packet结构与定义
Client 向 HDFS 写数据,数据会被组装成 Packet,然后发送到 Datanode 节点。Packet 分为两类,一类是实际数据包,另一类是 heatbeat 包。
packet 相关参数如下:
| 参数名称 | 参数值 | 参数含义 |
|---|---|---|
| chunkSize | 512+4=516 | 每个chunk的字节数(数据+校验和) |
| csize | 512 | 每个chunk数据的字节数 |
| psize | 64*1024 | 每个packet的最大字节数(不包含header) |
| DataNode.PKT_HEADER_LEN | 21 | 每个packet的header的字节数 |
| chunksPerPacket | 127 | 组成每个packet的chunk的个数 |
| packetSize | 25+516*127=65557 | 每个packet的字节数(一个header+一组chunk) |
Packet数据包的组成结构,如图所示:
二、读文件过程
在 HDFS 文件系统上读取一个文件,流程如下图所示:
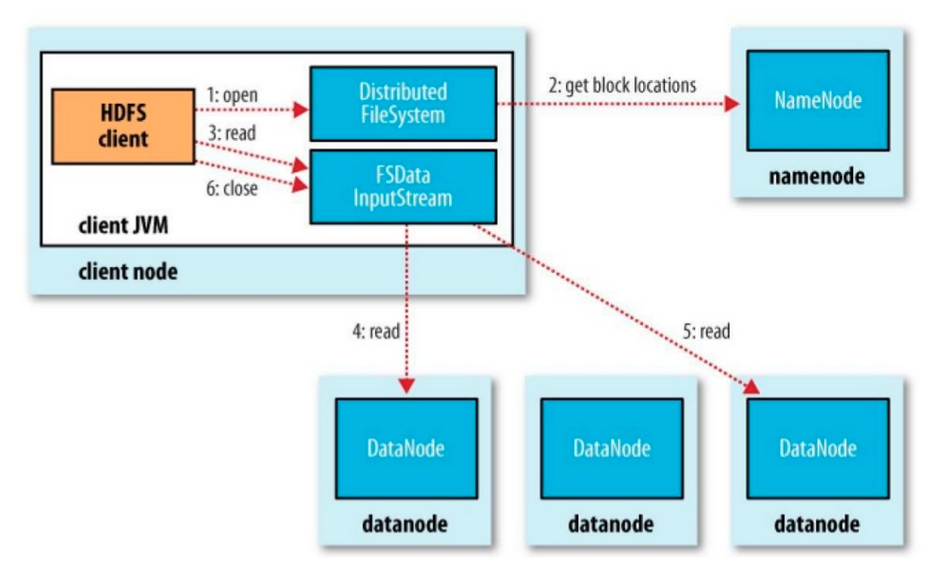
- Client 调用 DistributedFileSystem 对象的 open 方法,创建一个文件输入流(FSDataInputStream)对象
- 通过 DistributedFileSystem 对象与 Hadoop 集群的 NameNode 进行一次RPC远程调用,确定需要打开的文件一批数据块的存储位置
- 通过 FSDataInputStream 对象,读取距离客户端最近的 datanode,该 datanode 读取完成后接着寻找下一个 datanode 节点并读取数据
- 继续询问 namenode 下一批数据块的 datanode 的位置
- 读取完成后调用 FSDataInputStream 的 close 方法结束整个流程